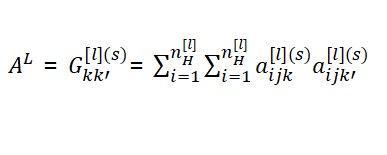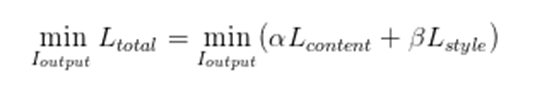논문 : Image-to-image translation with conditional adversarial networks.
저자 : Isola, P., Zhu, J. Y., Zhou, T., & Efros, A. A. (2017)

Why do we choose cGAN?
# CNN과의 차이점
-어떻게 최소화 하는지 방법을 알려주어야 하는데, 그 과정에서 유클리디안 방식을 사용
-유클리디안 방식을 사용하면 흐리게 나옴(모든 출력의 평균을 최소화 하기 때문)
→ 목표 : 출력 이미지를 현실과 구별할 수 없게 내놓으면서도 목적에 맞게 로스 함수를 자동으로 학습
|
기존 방식
|
Conditional GANs
|
|
•픽셀 단위의 classification or regression으로 문제 해결
•각 출력 픽셀들은 다른 픽셀들에 서로 독립적이라고 생각
•Unstructured 출력 공간 개념
|
•Structured loss 사용
: 주어진 목표 이미지와 출력의 다름을 penalize 하는 것
•Generator은 U-net 사용
•Discriminator은 PatchGAN 사용
|
# cGAN
G,D에 특정 condition을 나타내는 정보 “y”를 더해줌
Generator G는 Discriminator D가 실제 이미지인지 구분하지 못하는 출력을 내도록 학습되고,
D는 Generator가 생성한 이미지를 “fakes”로 구별할 수 있도록 훈련된다.

※ Z가 필요한가?
-Z의 유무가 큰 영향을 끼치지는 않지만, deterministic한 결론을 피하기 위해 dropout 형태로 여러 layer에 노이즈 줌
* Deterministic : 입력값에 다라 출력값이 결정되는 것.
* Dropout : 네트워크의 일부를 생략, 모델결합에 투표효과를 주어 신경망 성능 향상
Method
# cGAN의 목적함수(Objective)
G는 목적함수를 최소화하는 방향으로, D는 최대화 하는 방향으로 나타냄
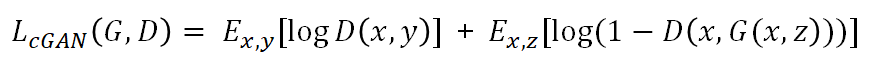
# L1 (맨하튼 거리)
격자 방식으로 픽셀상 거리를 나타냄, L2 유클리디안 거리는 블러리한 이미지 만들어냄

# 최종 목적함수(Objective)
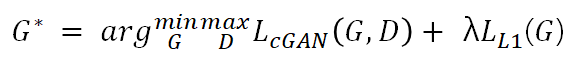
Generator with skips
•이전에는 입력이 여러 레이어를 통하면서 점점 다운샘플링 되고, 병목 레이어를 통화하고 나면 이러한 과정을 거꾸로 진행하는 처리
•입력과 출력 사이에서 저수준의 정보를 공유 → 더 좋은 화질의 이미지 출력 가능
•층 i과 층 n−i를 잇는 skip connection을 만듬 (n은 전체 층의 수)
•각 skip connection은 층 i의 모든 채널을 그대로 n−i층에 붙어있음

Markovian discriminator (PatchGAN)
#PatchGAN이란?
•전체 영역이 아니라 특정 크기의 patch 단위로 가짜/진짜를 판별하고 그 결과에 평균을 구하는 방식
•L1은 저주파 영역을 감당하고 D는 고주파 성분에 집중하여 가짜/진짜 여부를 판단함
•픽셀들간의 연관성을 거리에 비례하여 작아짐(일정거리 이상 떨어지면 상호간의 관계가 의미가 없어짐)
•특정 크기의 patch에 대하여 선명한 이미지 생성 비율을 찾고 학습을 한다면 G의 성능은 향상됨
•전체 이미지의 가짜/진짜를 가리는 것보다 상관관계가 유지되는 범위의 적절한 크기를 정하는 것이 효율적임
Conclusion
# L1 + cGAN
•전반적으로 보면 cGAN이 GAN보다, 그리고 L1과의 combination이 더 좋은 결과를 내어줌.
•D에 Conditioning이 없는, 즉 D가 x를 보지 않는 모델(GAN이라 표기/G에는 있음)은
사실 인풋과 아웃풋의 mismatch를 따지는 모델이 아니기 때문에 이 metric에서는 안좋은 성능일 수 밖에 없음.
•L1을 사용한다는 것 ⇒ Discriminator가 하는 일은 변함이 없지만, G는 D를 속이는 일 뿐 아니라
ground truth와의 L1 distance를 줄이는 일을 동시에 함
•cGAN은 (특정) input과 비슷한 (특정) output을 생성하도록 지도받음
•L1 loss는 ground truth와 생성된 output이 서로 비슷해지도록 지도함

# Colorfulness
•cGAN의 color distribution이 ground truth와 얼마나 matching하는지에 대한 표 (빨간색)
•L1 이 더 narrow한 distribution을 보이는데, averaged / grayish color를 만들어내기 때문
•cGAN이 더 실제에 가까운 color distribution을 보임
# Fully-convolutional translation
•PatchGAN은 고정된 패치 discriminator를 사용하므로 어떠한 이미지 크기에도 적용할 수 있다.
•마찬가지로 generator또한 복잡하게 적용할 수 있으므로 학습할 때 보다 더 큰 이미지에도 적용할 수 있다.
•256*256으로 학습했지만 512*512로 결과물을 낼 수 있음

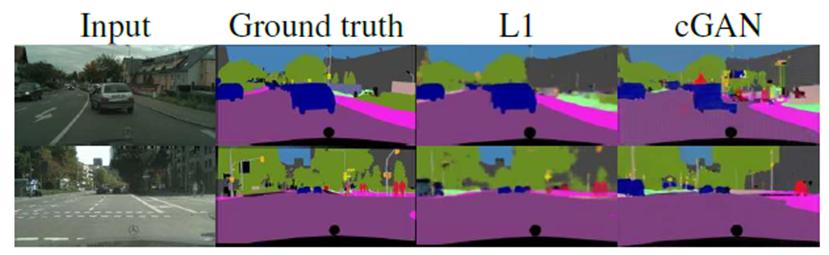
# Semantic segmentation (영상분할)
•아웃풋이 복잡하지 않을 때, 반대로 실험해본 결과
•Photo에서 Lables로 바뀌는 값은 L1 loss만 사용하는 방법이 더 효과적
•cGAN이 더 샤프한 아웃풋을 내주지만, 존재하지 않는 작은 오브젝트를 만들어냄
각각의 Traning Data에서 최대 3000장 정도가 사용/Architecture에서 Photo로 바꾸는 경우에는 400장밖에 사용
또한, training 시 batch size를 1 또는 4로 작게 가져가고 4일때는 Batch Normalization을 1일때는 Instance Normalization을 사용
온라인에서도 변환가능 https://affinelayer.com/pixsrv/index.html