CNN Sequential 모델 학습¶
In [0]:
# 런타임 -> 런타임 유형변경 -> 하드웨어 가속도 TPU변경
%tensorflow_version 2.x
#런타임 -> 런타임 다시시작
In [0]:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
1. Importing Libraries¶
In [0]:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.utils import to_categorical # one-hot 인코딩
import numpy as np
import matplotlib.pyplot as plt
import os
print(tf.__version__) # 텐서플로우 버전확인 (colab의 기본버전은 1.15.0) --> 2.0 변경 "%tensorflow_version 2.x"
print(keras.__version__) # 케라스 버전확인
2. Hyper Parameters¶
In [0]:
learning_rate = 0.001
training_epochs = 50
batch_size = 100
3. MNIST Data¶
In [0]:
mnist = keras.datasets.mnist
class_names = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
In [0]:
# MNIST image load (trian, test)
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 0~255 중 하나로 표현되는 입력 이미지들의 값을 1 이하가 되도록 정규화
train_images = train_images.astype(np.float32) / 255.
test_images = test_images.astype(np.float32) / 255.
# np.expand_dims 차원을 변경
train_images = np.expand_dims(train_images, axis=-1)
test_images = np.expand_dims(test_images, axis=-1)
# label을 ont-hot encoding
train_labels = to_categorical(train_labels, 10)
test_labels = to_categorical(test_labels, 10)
4. Model Function¶
In [0]:
# Sequential 모델 층 구성하기
def create_model():
model = keras.Sequential() # Sequential 모델 시작
model.add(keras.layers.Conv2D(filters=32, kernel_size=3, activation=tf.nn.relu, padding='SAME',
input_shape=(28, 28, 1)))
model.add(keras.layers.MaxPool2D(padding='SAME'))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3, activation=tf.nn.relu, padding='SAME'))
model.add(keras.layers.MaxPool2D(padding='SAME'))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, activation=tf.nn.relu, padding='SAME'))
model.add(keras.layers.MaxPool2D(padding='SAME'))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(256, activation=tf.nn.relu))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10, activation=tf.nn.softmax))
return model
In [0]:
model = create_model() # 모델 함수를 model로 변경
model.summary() # 모델에 대한 요약 출력해줌
5. Training¶
In [0]:
# CNN 모델 구조 확정하고 컴파일 진행
model.compile(loss='categorical_crossentropy', # crossentropy loss
optimizer='adam', # adam optimizer
metrics=['accuracy']) # 측정값 : accuracy
# 학습실행
history = model.fit(train_images, train_labels, # 입력값
batch_size=batch_size, # 1회마다 배치마다 100개 프로세스
epochs=training_epochs, # 15회 학습
verbose=1, # verbose는 학습 중 출력되는 문구를 설정하는 것
validation_data=(test_images, test_labels)) # test를 val로 사용
score = model.evaluate(test_images, test_labels, verbose=0) # test 값 결과 확인
print('Test loss:', score[0])
print('Test accuracy:', score[1])
6. Visualization¶
In [0]:
import matplotlib.pyplot as plt
import numpy as np
import os
# 모델 학습 후 정보가 담긴 history 내용을 토대로 선 그래프를 그리는 함수 설정
def plot_acc(history, title=None): # Accuracy(정확도) Visualization
# summarize history for accuracy
if not isinstance(history, dict):
history = history.history
plt.plot(history['accuracy']) # accuracy
plt.plot(history['val_accuracy']) # validation accuracy
if title is not None:
plt.title(title)
plt.ylabel('Accracy')
plt.xlabel('Epoch')
plt.legend(['Training data', 'Validation data'], loc=0)
# plt.show()
def plot_loss(history, title=None): # Loss Visualization
# summarize history for loss
if not isinstance(history, dict):
history = history.history
plt.plot(history['loss']) # loss
plt.plot(history['val_loss']) # validation
if title is not None:
plt.title(title)
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Training data', 'Validation data'], loc=0)
# plt.show()
In [0]:
# Visualization
plot_acc(history, '(a) Accuracy') # 학습 경과에 따른 정확도 변화 추이
plt.show()
plot_loss(history, '(b) Loss') # 학습 경과에 따른 손실값 변화 추이
plt.show()


'IT 공방 > Python' 카테고리의 다른 글
| tensorflow 2.0 CNN(functional model.fit) (0) | 2020.01.23 |
|---|---|
| tensorflow 2.0 CNN(sequential GradientTape) (0) | 2020.01.23 |
| train.exponential_decay (0) | 2020.01.03 |
| colab(코랩)에서 ipynb 파일을 html로 저장하기 (0) | 2019.12.10 |
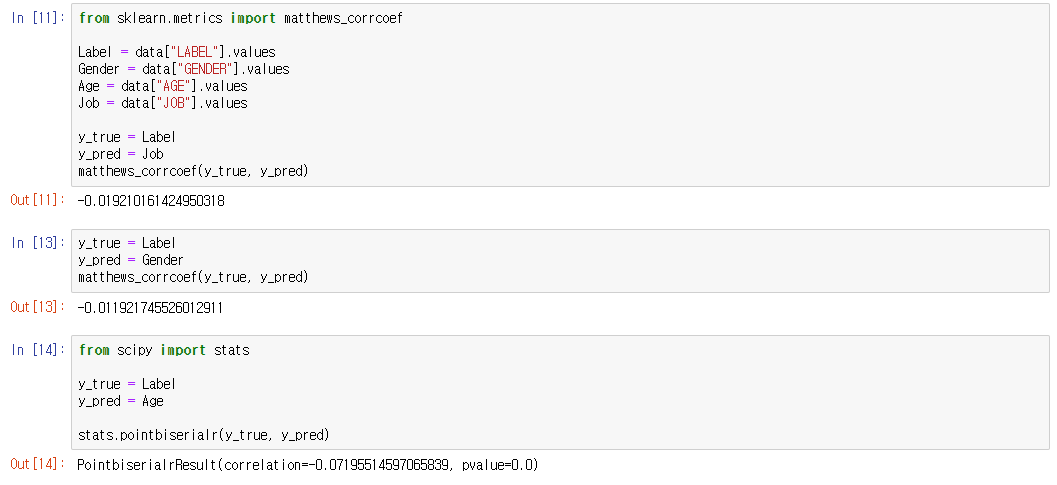
| python으로 상관관계 분석하기 (이산형자료) (0) | 2019.11.25 |